
前言
Linux 内核中的 elevator layer 就是 IO 调度层
之所以把 IO 视为电梯,是因为它的物理特性和生活上的电梯差不多:
- 消费者(电梯)远跟不上生产者(乘客等待上下楼)的速度
- 寻址方式说是随机访问(到哪都行),其实条件苛刻(反方向哪怕只差一个楼层,也可能等半天)
deadline 是 elevator 层中提供的一种具体调度算法,它只需实现 elevator 通用框架提供的一些接口即可提供 IO 调度能力
选 deadline 作为本篇主角的原因是:
这个比较好懂(CFQ BFQ 写的什么鬼)- 知道 IO 优化面临的问题,和对应的解决方案
- 流程较短,顺便了解一下 block layer
注:由于历史原因,本文基于 4.18.20
前置知识之块 IO 层
尽管 deadline 算法只有 500 行,但是直接看源码也是一头雾水的——你连它从哪里来,到哪里去都不知道,甚至连回调接口的参数类型也不知道是什么意思,这代码怎么读?
因此先上架构图(水时长)
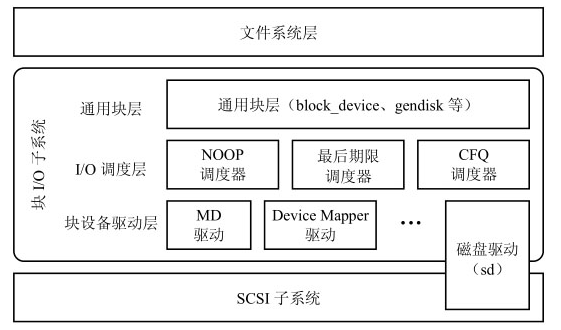
可以看到,block IO 分为三层:
- 通用块层
- IO 调度层
- 块设备驱动层
除了 IO 调度层以外,还有通用块层和块设备驱动层:前者大概是用于对具体设备做出一个抽象层,提供磁盘描述符、设备号映射机制等作用;后者就是引入 MD 和 DM 概念,比如 RAID 支持
我们这里关注的,就是 elevator 的调度。从代码上来说,就是上层(VFS、mapper layer、具体文件系统)通过 submit_bio() 构造了一个 IO 请求 bio;流经到 IO 调度层,经过 elevator 的调整(合并、排序)转换为另一个 IO 请求 request;再下发到更下层的 IO 栈,此时 IO 请求可能已经成为一个面向驱动的命令,还是别的概念
现在知道了它的来源和去处
前置知识之 IO 请求
既然说到 IO 请求,那就需要理清一下前面提到的 bio 和 request 的关系
见下图
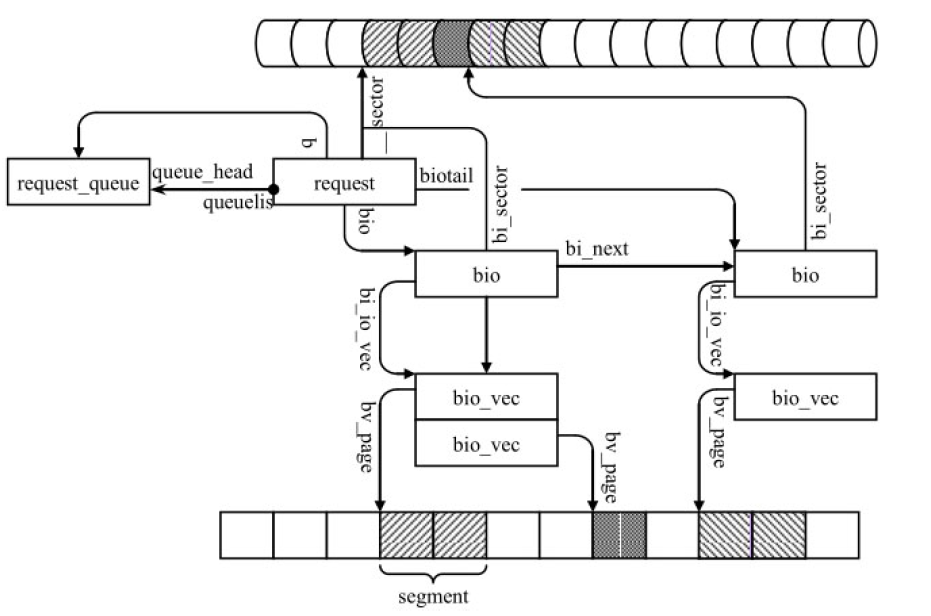
先从 bio 往下(bio_vec、segment)看起
bio 是由众多 bio_vec 维护,bio_vec 描述一个段 segment:从哪开始,长度多少
这些 segment 由 struct page 组成:page 可以作为一种寻址上的抽象,提供逻辑块号
可以注意到,一个 bio 多个 bio_vec,它们各自指向的 segment 是允许离散的:因为它们访问的是逻辑块
但是落地到物理扇区,还是需要连续的,这就是 bi_sector 实际指向的位置。要得到它,是先要初始化好 segment,再通过具体文件系统和 mapper layer 的配合才能拿到这些 sector 值(这是另一个故事了)
而 request,则可以有多个 bio 组成,通过 bio 间的 bi_next 字段就能找到属于这个 request 的所有 bio
同样,维护众多 request 的 request_queue 也可通过 queuelist 字段访问到属于它的所有 request
elevator 通用框架
elevator 经过有哪些通用流程就不细说了(我也没看啊,天天催干活哪来这么多时间看)
需要了解的是,框架给了很多接口(下表为节选),并且调度器只需要实现一部分即可
| 接口 | 注释 |
|---|---|
elevator_merge_fn |
called to query requests for merge with a bio |
elevator_merge_req_fn |
called when two requests get merged. the one which gets merged into the other one will be never seen by I/O scheduler again. IOW, after being merged, the request is gone. |
elevator_merged_fn |
called when a request in the scheduler has been involved in a merge. It is used in the deadline scheduler for example, to reposition the request if its sorting order has changed. |
elevator_dispatch_fn* |
fills the dispatch queue with ready requests. I/O schedulers are free to postpone requests by not filling the dispatch queue unless @force is non-zero. Once dispatched, I/O schedulers are not allowed to manipulate the requests - they belong to generic dispatch queue. |
elevator_add_req_fn* |
called to add a new request into the scheduler |
elevator_former_req_fn |
|
elevator_latter_req_fn |
These return the request before or after the one specified in disk sort order. Used by the block layer to find merge possibilities. |
elevator_completed_req_fn |
called when a request is completed. |
最常见的就是 add_req 操作,把一个 request 加入到 IO 调度队列里头
或者 merge 操作,把 bio 合入到 request 中,或者两个 request 之间合并
最后是 dispatch 操作,把 request 派发到下层的派发队列(dispatch queue)中
这里需要澄清的是,elevator 层的调度发生于 IO 调度队列:这个“队列”是个抽象的概念,它可以是个数组、红黑树,也可以为空,取决于具体调度实现算法(后面就会看到 deadline 的 IO 调度队列形式)
而上述注释中的 dispatch queue,我这里翻译为派发队列,可以认为进入到这个队列就是往下层走,逐渐脱离 elevator 层
deadline 数据结构
elevator 通用框架为具体调度算法提供自定义数据结构的机制
可以通过 struct elevator_queue 中的 void *elevator_data 字段获取
在 deadline 中,它实现的数据结构如下所示
struct deadline_data {
/*
* run time data
*/
/*
* requests (deadline_rq s) are present on both sort_list and fifo_list
*/
struct rb_root sort_list[2];
struct list_head fifo_list[2];
/*
* next in sort order. read, write or both are NULL
*/
struct request *next_rq[2];
unsigned int batching; /* number of sequential requests made */
unsigned int starved; /* times reads have starved writes */
/*
* settings that change how the i/o scheduler behaves
*/
int fifo_expire[2];
int fifo_batch;
int writes_starved;
int front_merges;
};
首先关注前两个字段,它们是实质的调度队列容器:
- 两棵红黑树,读写请求各一棵
- 两个 FIFO 队列,读写请求各一队
- 一个
request,既存在于红黑树,也存在于 FIFO - 红黑树按 sector 作为 key 排序,而 FIFO 按超时时间插入
(注:由于超时的时间点是递增的,所以 FIFO 就是直接插入,先进先出)
易行有效的优化手段
我们从调度队列中注意到什么?deadline 关注到几个优化的点:
- sector 排序
- 请求超时阈值
- 读写分离
sector 排序算是 IO 调度的共识了,可以使得硬件尽可能提供顺序访问,提高 IO 的吞吐量
超时阈值很显然与 deadline 这个名词有关。固定的 IO 顺序访问策略虽然有助于提高吞吐量,但可能会使得某些非顺序的 IO 请求等待延迟过大。因此,我们需要为一个 IO 请求的最坏处理时间做出担保,当 IO 请求的等待延迟达到一定的阈值时,将会优先处理
读写分离是个有意思的观点。可以这么认为,在多数情况下,读请求是需要同步处理的,而写请求更多是异步处理,即读操作需要及时处理,否则易造成 IO 上的 block 现象。为此,红黑树和 FIFO 队列都分离出读容器和写容器,在一般情况下,更倾向于优先获取读容器内的 request。以 FIFO 为例,这种读写优先级分离的思想仍然存在,FIFO 中的读操作的超时时间是 500ms,而写操作则宽容到 5s
权衡利弊:batching 和 starved 机制
batching 和 starved 是运行时维护的字段,而 fifo_batch 和 writes_starved 则是一个限定的阈值,后者分别为 16 和 2
batching
先来看 batching 机制。这是关于 IO 顺序访问的 workaround。
next_rq[2] 数组用于维护下一个 sector 有序的读请求或写请求(每次红黑树删除结点时顺手拿出,降低时间复杂度常数),它们是互斥的,既下标 0(读)或下标 1(写)其一非空。
因此 dispatch 阶段直接从 next_rq 取出可用的请求即可,保持寻址一路向前。
这种做法产生的问题是:反方向的请求会造成饥饿。
deadline 的解决方案是提供 batching 计数,最多允许优先直接从 next_rq 拿 batching 次,超过则至少要强制且成功从 FIFO 中拿到一次请求后才重新计数(注意:这里 FIFO 同样是读写分离,并优先从读 FIFO 中拿出)
这种做法是满足 deadline 语义的同时重新确认顺序执行的起始 sector,即解决反向请求问题的同时处理即将超时的任务,也不会对后续顺序请求造成失效
starved
再说 starved 机制。很显然前面的读写分离、读尊写卑的思想会导致写饥饿问题,因此时域上不好衡量的问题(等多久才给一次写请求的机会?)就从频域来看,每 writes_starved 次读请求后需要有一次写请求的参与。这方法是不是简单又实用?
小疑问:前向合并
IO 请求合并一般分为前向合并和后向合并。比如说,把刚来的 bio 请求放入到 request 的 bio 链表最后面就是后向合并
合并的判断就很简单了,bio 有 sector 位置,那就直接往红黑树里头查找对应的边界就好了
deadline 只提供前向合并,开关由 front_merges 控制
其实我也想知道为什么不提供后向?
(kernel doc 中的描述反而感觉有些矛盾)
看看代码
链接如下,相信对照前面的介绍基本都能看明白
block/deadline-iosched.c - Linux source code (v4.18.20) - Bootlin
总结
2018 年退役的时候,偶然看到一本开源书的标题——500 lines or less
大意就是用 500 行甚至更短的代码干完一件了不起的事情
其实现在看到的 deadline 也是恰好 500 行的量级
那么它的 500 行教会你什么?
- 基本的 IO 优化策略,对 IO 进行合并与排序
- 针对排序执行的问题,引入超时保底以解决无法覆盖的极端场合
- 最关键的指出读与写的不同特性,并依此提出优先级的概念
- 发现并针对上述可能产生写饥饿的问题,提供缓解方案
- 一些数据结构上的小技巧,做法很简单,但显然是经过考虑而设计的
说到底就是一个发现并解决问题的过程。500 行左右就能做到,我觉得很了不起了
References
《存储技术原理分析》
https://www.kernel.org/doc/Documentation/block/deadline-iosched.txt
域名迁移,网址会自动跳转
如果没有响应,请点击这里